 |
SyTen
|


|
|
SyTen
|
|

CUDA can be used to speed up computations if a GPU exists on the system. In particular large tensor-tensor products benefit tremendously.
CUDA support is implemented via a variant of the syten::GenericDenseTensor struct. This means that a single full tensor (syten::Tensor or syten::STensor) can contain some blocks hosted by the GPU and some blocks stored in main memory. Operations on blocks then either occur in main memory only (if both blocks are there), on the GPU only (if both blocks are there) or one of the two blocks is copied on-the-fly either to main memory (if both are smaller than a configured threshold, syten::EnvVars::cuda_size_to_gpu) or the GPU (if both are larger).
To enable compilation of CUDA, set SYTEN_USE_CUDA, e.g. by adding
to your make.inc file. When this flag is set, some custom CUDA kernels are compiled using the NVCC and NVCCFLAGS_EXTRA variables which you may need to set, for example:
to use an older GCC. If you do not set SYTEN_USE_CUDA, most of the Cuda code (e.g. the syten::CudaDenseTensor class) is still compiled, but uses the standard host memory and host CPU operations on runtime. Once the flag is set and the CUDA code and kernels are compiled, it makes sense to enable CUDA support at runtime. To do so, set the SYTEN_CUDA_DEVICES environment variable or pass the --cuda-devices= command line option.
CUDA devices are enumerated with non-negative integers. You can also pass the special value -1 to automatically select the device which (at startup time) has the most free memory (i.e., --cuda-devices=-1). You can allow multiple devices using a comma-separated list (--cuda-devices=0,1). Note that inter-device data transfer is very slow.
You can set syten::EnvVars::cuda_size_to_gpu either via the SYTEN_CUDA_THRESHOLD environment variable or the --cuda-size-to-gpu command line option.
Each cuBLAS call needs a handle, which can be reused serially but not used in parallel (contrary to what the documentation claims). A number of these handles are allocated per device initially, you can set this number using SYTEN_CUDA_NUM_HANDLES.
If your GPU has compute capability 6.0, you may define the macro SYTEN_CUDA_HAS_ATOMIC_ADD (you likely also have to add -arch=sm_60 to your NVCCFLAGS_EXTRA variable above). When doing so, you enable a naive custom CUDA kernel for complex numbered scalar products which slightly outperforms the standard cublasdotZc.
When writing a code, it may be helpful to use the GPU at some point. To this end, syten::Tensor and syten::STensor have functions syten::Tensor::maybe_make_dense_cuda() and syten::STensor::maybe_make_dense_cuda(). Calling this function causes blocks above the threshold size to be moved to the GPU if CUDA support is compiled in and CUDA support is enabled at runtime. You can likewise move tensors to the CPU (via syten::Tensor::make_dense_standard()) or force them to be moved to CUDA allocations regardless of compilation status (via syten::Tensor::make_dense_cuda()). The latter is in particular helpful for testing, as most of the code paths can be executed on non-CUDA devices as well.
For some operations, CUDA kernels already exist. By convention, CUDA kernel header files should contain cukrn, CUDA kernel compilation units must have the same name and end on .cu (for the Makefile to detect this). The .cu file and the header should both be empty if SYTEN_USE_CUDA is undefined. The functions defined in the header should be called from a non-cukrn file which alternatively redirects the call to a (possibly much slower) CPU implementation if SYTEN_USE_CUDA is undefined. Note that the *_cukrn.h and *_cukrn.cu files need to be understood by NVCC, which often only supports an old compiler. You should hence avoid including other toolkit files in those headers, which means that most setup (e.g. allocating workspace memory) will have to be done in the calling non-cukrn file.
To add your own kernel, take a look at the existing ones in inc/dense/*cukrn.cu.
cudaMalloc() and cudaFree() are really slow. A custom allocator, defined and implemented in inc/util/cuda_support.cpp, takes care of memory allocation at runtime using a buddy allocator: A large block is obtained initially. To obtain a block of half the size, the large block is split into two, one of the two halves is used and the other is added to a free list. Once the first half is also freed (and added to the free list), the two halves are combined again and added to the larger free list as a single block.
The largest block allocated by this allocator is set via SYTEN_CUDA_ALLOC_MAX (as two to the power of this value, by default 4GB) and the smallest given-out block is set by SYTEN_CUDA_ALLOC_MIN (meaning all allocations are at least two to the power of this value large, by default 256 Byte).
Note that if your application crashes on start-up and your GPU has just about 4GB of memory (or less), you may need to set SYTEN_CUDA_ALLOC_MAX to a smaller value (e.g. 31 for 2 GB or 29 for 512 MB).
The current implementation (as of 7dcffb13) does not support SVDs (or QRs or Eigensolver decompositions) on the GPU. In principle, doing them there may be helpful, as it would avoid GPU-CPU memory transfers. However, the cuSolver SVD implementation is supposedly not much faster than LAPACK/MKL and potentially buggy. Properly truncating the singular values will also require a fair amount of custom CUDA kernel codes.
Streams are a way to parallelise execution on the GPU by asynchronously queuing multiple work items onto a stream, only waiting for the last one to complete and also allowing the GPU to work on multiple such streams simulatenously (if a single one is not occupying it up completely).
CUDA streams guarantee sequential completion of work: Enqueuing three work items sequentially into a stream ensures that the work items are worked on in sequential order and that e.g. the second one can depend on the output of the first one. Enqueuing three work items into three different streams does not guarantee sequential completion of the work and hence requires the work items to be independent.
This sequential work is not too well applicable to the present SyTen infrastructure. Streams are hence only used at the lowest level to ensure inter- and intra-device synchronisation and to allow multiple kernels to run on the GPU simulatenously (e.g. when working on multiple blocks in different OpenMP threads), but they are not used at any higher levels.
One obvious area of improvement would be to rewrite tensor-tensor products from the ground up to use both CUDA streams and not to transpose tensors on-demand but instead only once per product.
The CUDA toolkit documentation, e.g. here is helpful. Read the CUDA Runtime API for information on how to call API functions (e.g. cudaMalloc()). The programming guide contains information on how to write your own kernels. The cuBLAS reference is also helpful. The buddy allocator is modelled after slides here, this page was also helpful.
To test the result, we use 2DMRG on a L=200 S=1/2 Heisenberg chain, at commit 7dcffb13. The initial state already has bond dimension m=2048 and is the ground state of the Heisenberg Hamiltonian. We now change the z coupling to 0.8 (from 1) and re-run two sweeps with 2DMRG. The GPU is a Tesla P100 with 16 GB of RAM. A single iteration fits easily, but we have to cache the other site tensors to disk (done using /ptmp at the TQO cluster, which is notoriously slow). After some optimisations, we find an acceptable speed-up between the now-fastest CPU version (CPUv4 below) and the fastest GPU version (GPUv5 below, with the custom allocator; GPUv4 has a custom transpose kernel).
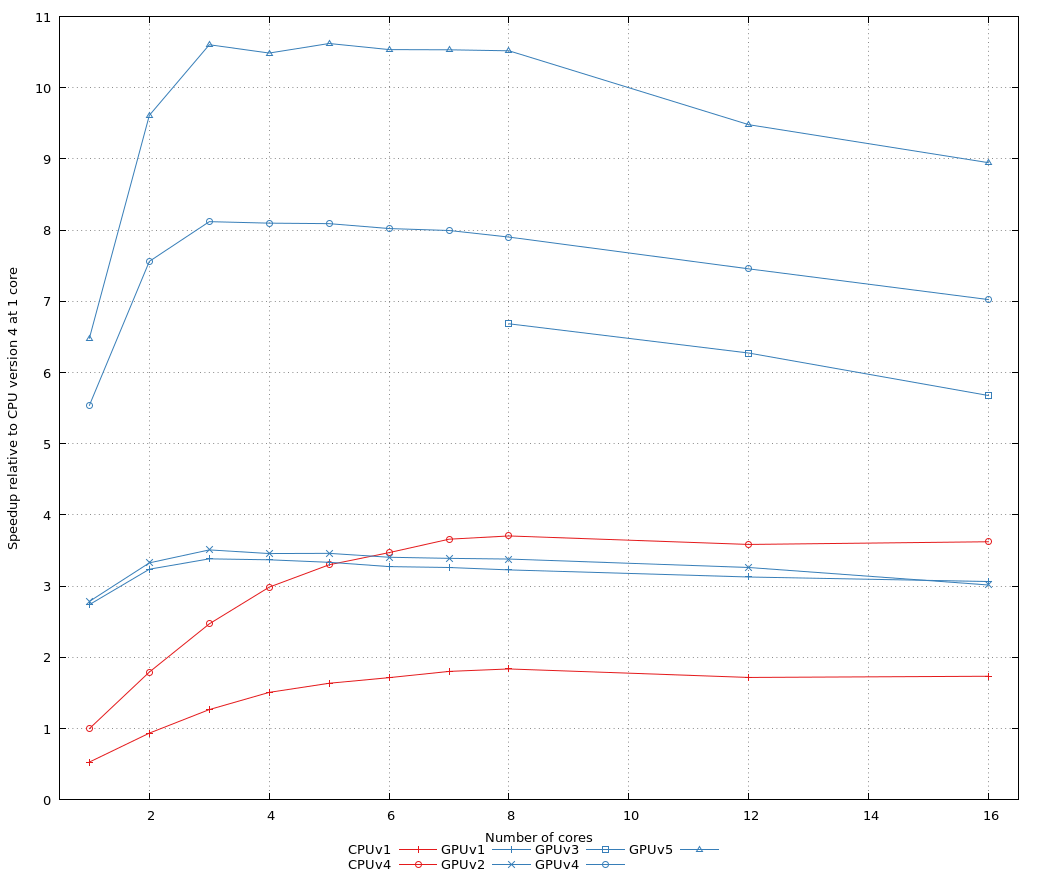
With 8 cores, the timing information for the second sweep with just CPUs was as follows:
while using a GPU and 8 CPU cores changes this to:
That is, an overall speed-up of 2.2e6/7.9e5 = 2.7 with the CPU-bound SVD now taking up half of the real time elapsed.